Статистика рассчитать дисперсию. Дисперсия, виды и свойства дисперсии
Наряду с изучением вариации признака по всей по всей совокупности в целом часто бывает необходимо проследить количественные изменения признака по группам, на которые разделяется совокупность, а также и между группами. Такое изучение вариации достигается посредством вычисления и анализа различных видов дисперсии.
Выделяют дисперсию общую, межгрупповую и внутригрупповую
.
Общая дисперсия σ 2
измеряет вариацию признака по всей совокупности под влиянием всех факторов, обусловивших эту вариацию, .
Межгрупповая дисперсия (δ) характеризует систематическую вариацию, т.е. различия в величине изучаемого признака, возникающие под влиянием признака-фактора, положенного в основание группировки. Она рассчитывается по формуле:
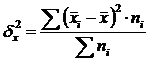 .
.
Внутригрупповая дисперсия (σ)
отражает случайную вариацию, т.е. часть вариации, происходящую под влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Она вычисляется по формуле:
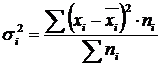 .
.
Средняя из внутригрупповых дисперсий
:  .
.
Существует закон, связывающий 3 вида дисперсии. Общая дисперсия равна сумме средней из внутригрупповых и межгрупповой дисперсии: ![]() .
.
Данное соотношение называют правилом сложения дисперсий
.
В анализе широко используется показатель, представляющий собой долю межгрупповой дисперсии в общей дисперсии. Он носит название эмпирического коэффициента детерминации (η 2):
.
Корень квадратный из эмпирического коэффициента детерминации носит название эмпирического корреляционного отношения (η)
:
 .
.
Оно характеризует влияние признака, положенного в основание группировки, на вариацию результативного признака. Эмпирическое корреляционное отношение изменяется в пределах от 0 до 1.
Покажем его практическое использование на следующем примере (табл. 1).
Пример №1 . Таблица 1 - Производительность труда двух групп рабочих одного из цехов НПО «Циклон»
Рассчитаем общую и групповые средние и дисперсии:
Исходные данные для вычисления средней из внутригрупповых и межгрупповой дисперсии представлены в табл. 2.
Таблица 2
Расчет и δ 2 по двум группам рабочих.
|
Группы рабочих | Численность рабочих, чел. | Средняя, дет./смен. | Дисперсия |
| Прошедшие техническое обучение | 5 | 95 | 42,0 |
| Не прошедшие техническое обучение | 5 | 81 | 231,2 |
| Все рабочие | 10 | 88 | 185,6 |
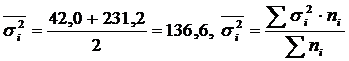 .
.
Межгрупповая дисперсия
Общая дисперсия:
Таким образом, эмпирическое корреляционное соотношение: .
Наряду с вариацией количественных признаков может наблюдаться и вариация качественных признаков. Такое изучение вариации достигается посредством вычисления следующих видов дисперсий:
Внутригрупповая дисперсия доли определяется по формуле
где n i – численность единиц в отдельных группах.Доля изучаемого признака во всей совокупности, которая определяется по формуле:
Три вида дисперсии связаны между собой следующим образом:
Это соотношение дисперсий называется теоремой сложения дисперсий доли признака.
Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
![]()
s 2 – дисперсия выборки;
x ср — среднее значение выборки;
n — размер выборки (количество значений данных),
(x i – x ср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.

Финальная фаза вычисления дисперсии выглядит так:
![]()
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.

— сумма каждого значения данных после возведения в квадрат,
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.


Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Расчет дисперсии в Excel
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.

Дисперсия случайной величины - мера разброса данной случайной величины , то есть её отклонения от математического ожидания. В статистике для обозначения дисперсии часто употребляется обозначение (сигма в квадрате). Квадратный корень из дисперсии , равный , называется стандартным отклонением или стандартным разбросом. Стандартное отклонение измеряется в тех же единицах, что и сама случайная величина, а дисперсия измеряется в квадратах этой единицы измерения.
Хотя для оценки всей выборки очень удобно использовать лишь одно значение (такое как среднее значение или моду и медиану), этот подход легко может привести к неправильным выводам. Причина такого положения лежит не в самой величине, а в том, что одна величина никак не отражает разброс значений данных.
Например, в выборке:
среднее значение равно 5.
Однако, в самой выборке нет ни одного элемента со значением 5. Возможно, Вам потребуется знать степень близости каждого элемента выборки к ее среднему значению. Или, другими словами, вам потребуется знать дисперсию значений. Зная степень изменения данных, Вы можете лучше интерпретировать среднее значение , медиану и моду . Степень изменения значений выборки определяется путем вычисления их дисперсии и стандартного отклонения.
Дисперсия и квадратный корень из дисперсии, называемый стандартным отклонением, характеризуют среднее отклонение от среднего значения выборки. Среди этих двух величин наибольшее значение имеет стандартное отклонение . Это значение можно представить как среднее расстояние, на котором находятся элементы от среднего элемента выборки.
Дисперсию трудно интерпретировать содержательно. Однако, квадратный корень из этого значения является стандартным отклонением и хорошо поддается интерпретации.
Стандартное отклонение вычисляется путем определения сначала дисперсии и затем вычисления квадратного корня из дисперсии.
Например, для массива данных, приведенных на рисунке, будут получены следующие значения:

Рисунок 1
Здесь среднее значение квадратов разностей равно 717,43. Для получения стандартного отклонения осталось лишь взять квадратный корень из этого числа.
Результат составит приблизительно 26,78.
Следует помнить, что стандартное отклонение интерпретируется как среднее расстояние, на котором находятся элементы от среднего значения выборки.
Стандартное отклонение показывает, насколько хорошо среднее значение описывает всю выборку.
Допустим, Вы являетесь руководителем производственного отдела по сборке ПК. В квартальном отчете говорится, что выпуск за последний квартал составил 2500 ПК. Плохо это или хорошо? Вы попросили (или уже в отчете есть эта графа) в отчете отобразить стандартное отклонение по этим данным. Цифра стандартного отклонения, например, равна 2000. Становится понятным для Вас, как руководителя отдела, что производственная линия требует лучшего управления (слишком большие отклонения по количеству собираемых ПК).
Вспомним: при большой величине стандартного отклонения данные широко разбросаны относительно среднего значения, а при маленькой – они группируются близко к среднему значению.
Четыре статистические функции ДИСП(), ДИСПР(), СТАНДОТКЛОН() и СТАНДОТКЛОНП() – предназначены для вычисления дисперсии и стандартного отклонения чисел в интервале ячеек. Перед тем как вычислять дисперсию и стандартное отклонение набора данных, нужно определить, представляют ли эти данные генеральную совокупность или выборку из генеральной совокупности. В случае выборки из генеральной совокупности следует использовать функции ДИСП() и СТАНДОТКЛОН(), а в случае генеральной совокупности – функции ДИСПР() и СТАНДОТЛОНП():
| Генеральная совокупность | Функция |
 | ДИСПР() |
 | СТАНДОТЛОНП() |
| Выборка | |
 | ДИСП() |
 | СТАНДОТКЛОН() |
Дисперсия (а так же стандартное отклонение), как мы отмечали, свидетельствуют о том, в какой степени входящие в набор данных величины разбросаны вокруг среднего арифметического.
Малое значение дисперсии или стандартного отклонения говорит о том, что все данные сосредоточены вокруг среднего арифметического, а большое значение этих величин – о том, что данные разбросаны в широком диапазоне значений.
Дисперсию достаточно трудно интерпретировать содержательно (что значит малое значение, большое значение?). Выполнение Задания 3 позволит визуально, на графике, показать смысл дисперсии для набора данных.
Задания
· Задание 1.
· 2.1. Дать понятия: дисперсия и стандартное отклонение; их символьное обозначение при статистической обработке данных.
· 2.2. Оформить рабочий лист в соответствии с рисунком 1 и произвести необходимые расчеты.
· 2.3. Привести основные формулы, используемые при расчетах
· 2.4. Пояснить все обозначения ( , , )
· 2.5. Пояснить практическое значение понятия дисперсия и стандартное отклонение.
Задание 2.
1.1. Дать понятия: генеральная совокупность и выборка; математическое ожидание и среднее арифметическое их символьное обозначение при статистической обработке данных.
1.2. В соответствии с рисунком 2 оформить рабочий лист и произвести расчеты.
1.3. Привести основные формулы, используемые при расчетах (для генеральной совокупности и выборке).

Рисунок 2
1.4. Объяснить, почему возможны получения таких значений средних арифметических в выборках как 46,43 и 48,78 (см. файл Приложение). Сделать выводы.
Задание 3.
Имеется две выборки с различным набором данных, но среднее для них будет одинаковым:

Рисунок 3
3.1. Оформить рабочий лист в соответствии с рисунком 3 и произвести необходимые расчеты.
3.2. Приведите основные формулы расчета.
3.3. Постройте графики в соответствии с рисунками 4, 5.
3.4. Поясните полученные зависимости.
3.5. Аналогичные вычисления проведите для данных двух выборок.
Исходная выборка 11119999
Значения второй выборки подбираете так, что бы среднее арифметическое для второй выборки было таким же, например,:

Подберите значения для второй выборки самостоятельно. Оформите вычисления и построения графиков подобно рисункам 3, 4, 5. Покажите основные формулы, которые использовали при вычислениях.
Сделайте соответствующие выводы.
Все задания оформить в виде отчета со всеми необходимыми рисунками, графиками, формулами и краткими пояснениями.
Примечание: построение графиков обязательно пояснить с рисунками и краткими пояснениями.
Вычислим в MS EXCEL дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим дисперсию , затем стандартное отклонение .
Дисперсия выборки
Дисперсия выборки (выборочная дисперсия, sample variance ) характеризует разброс значений в массиве относительно .
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего , деленная на размер выборки минус 1.
дисперсии выборки используется функция ДИСП() , англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог ДИСП.В() , англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция ДИСП.Г(), англ. название VARP, т.е. Population VARiance, которая вычисляет дисперсию для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у ДИСП.В() , у ДИСП.Г() в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция ДИСПР() .
Дисперсию выборки
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1
) –
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению . Обычно, чем больше величина дисперсии , тем больше разброс значений в массиве.
Дисперсия выборки является точечной оценкой дисперсии распределения случайной величины, из которой была сделана выборка . О построении доверительных интервалов при оценке дисперсии можно прочитать в статье .
Дисперсия случайной величины
Чтобы вычислить дисперсию случайной величины, необходимо знать ее .
Для дисперсии случайной величины Х часто используют обозначение Var(Х). Дисперсия равна квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X)) 2 ]
дисперсия вычисляется по формуле:

где x i – значение, которое может принимать случайная величина, а μ – среднее значение (), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет , то дисперсия вычисляется по формуле:

Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение .
Некоторые свойства дисперсии :
Var(Х+a)=Var(Х), где Х - случайная величина, а - константа.
Var(aХ)=a 2 Var(X)
Var(Х)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)-2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Это свойство дисперсии используется в статье про линейную регрессию .
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y - случайные величины, Cov(Х;Y) - ковариация этих случайных величин.
Если случайные величины независимы (independent), то их ковариация равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе .
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1) 2 Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения .
Стандартное отклонение выборки
Стандартное отклонение выборки - это мера того, насколько широко разбросаны значения в выборке относительно их .
По определению, стандартное отклонение равно квадратному корню из дисперсии :

Стандартное отклонение не учитывает величину значений в выборке , а только степень рассеивания значений вокруг их среднего . Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется Коэффициент вариации (Coefficient of Variation, CV) - отношение Стандартного отклонения к среднему арифметическому , выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция =СТАНДОТКЛОН() , англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог =СТАНДОТКЛОН.В() , англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция СТАНДОТКЛОН.Г() , англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет стандартное отклонение для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у СТАНДОТКЛОН.В() , у СТАНДОТКЛОН.Г() в знаменателе просто n.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера
)
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1))
=КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Другие меры разброса
Функция КВАДРОТКЛ() вычисляет сумму квадратов отклонений значений от их среднего . Эта функция вернет тот же результат, что и формула =ДИСП.Г(Выборка )*СЧЁТ(Выборка ) , где Выборка - ссылка на диапазон, содержащий массив значений выборки (). Вычисления в функции КВАДРОТКЛ() производятся по формуле:

Функция СРОТКЛ() является также мерой разброса множества данных. Функция СРОТКЛ() вычисляет среднее абсолютных значений отклонений значений от среднего . Эта функция вернет тот же результат, что и формула =СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка) , где Выборка - ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции СРОТКЛ () производятся по формуле:

В случае, если совокупность разбита на группы по изучаемому признаку, то для данной совокупности могут быть исчислены следующие виды дисперсии: общая, групповые (внутригрупповые), средняя из групповых (средняя из внутригрупповых), межгрупповая.
Первоначально рассчитывает коэффициент детерминации, который показывает какую часть общей вариации изучаемого признака составляет вариация межгрупповая, т.е. обусловленная группировочным признаком:
Эмпирическое корреляционное отношение характеризует тесноту связи между признаками группировочным (факторным) и результативным.
Эмпирическое корреляционное отношение может принимать значения от 0 до 1.
Для оценки тесноты связи на основе показателя эмпирического корреляционного отношения можно воспользоваться соотношениями Чеддока:
Пример 4. Имеются следующие данные о выполнении работ проектно-изыскательскими организациями разной формы собственности:
Определить:
1) общую дисперсию;
2) групповые дисперсии;
3) среднюю из групповых дисперсий;
4) межгрупповую дисперсию;
5) общую дисперсию на основе правила сложения дисперсий;
6) коэффициент детерминации и эмпирическое корреляционное отношение.
Сделайте выводы.
Решение:
1. Определим средний объём выполнения работ предприятий двух форм собственности:
Рассчитаем общую дисперсию:
![]()
2. Определим групповые средние:
![]() млн руб.;
млн руб.;
![]() млн руб.
млн руб.
Групповые дисперсии:
![]() ;
;
3. Рассчитаем среднюю из групповых дисперсий:
4. Определим межгрупповую дисперсию:
5. Рассчитаем общую дисперсию на основе правила сложения дисперсий:
6. Определим коэффициент детерминации:
![]() .
.
Таким образом, объём работ, выполненных проектно-изыскательскими организациями на 22% зависит от формы собственности предприятий.
Эмпирическое корреляционное отношение рассчитываем по формуле
![]() .
.
Величина рассчитанного показателя свидетельствует о том, что зависимость объема работ от формы собственности предприятия невелика.
Пример 5. В результате обследования технологической дисциплины производственных участков получены следующие данные:
Определите коэффициент детерминации